AI蓝皮书:GPT-SoVITS文本转语音入门教程(含SillyTavern酒馆接入)
SillyTavern(酒馆/AI猫娘)系列
[展开/折叠]-
SillyTavern(酒馆)从入门到精通
喂饭式教学,不可能学不会
-
手机(Android)安装布置教程
随时随地逗逗猫娘的方法
-
免费VPS服务器租用和布置教程
通过第三方服务器开设酒馆教程
-
各种技巧/插件的说明
玩酒馆必看的进阶教程
-
GPT-SoVITS文本转语音入门教程(含SillyTavern酒馆接入)
AI语音合成,提升沉浸感的好方法
-
酒馆本地跑文字模型测试和推荐
当前还不太行的本地模型测评
-
盘点支持免费API调用的AI服务
需要免费接入酒馆的AI,来看这里吧
-
Gemini反代,免费API调用Gemini 3 pro模型
当前酒馆免费接入的AI中效果最好的选择!
在很早之前的SillyTavern(酒馆)从入门到精通教程中,BLOG就介绍过文字转语音(TTS)服务的使用。但是由于当时只介绍了EDGE在线和Microsoft本地合成,这两者仅仅是提供了发声这个功能,距离流畅、自然的语音那是相差甚远。最近BLOG主自己也经常需要做一些讲解视频,写好了稿子就想找个AI合成一下语音,但是腾讯之类的在线TTS实在是太弱智了,不仅慢而且效果差。痛定思痛,BLOG主决定正式开搞本地TTS,一劳永逸地解决当前遇到的问题。
如题目可跳转到github项目,GPT-SoVITS是当前使用频率较高,对接酒馆比较方便的一个通用的TTS可训练开源模型。当前二次元中使用的频率比较高。AI Hobbyist社区也有不少玩家分享了原神、绝区零、崩铁、明日方舟的大量角色预训练模型,可以说做到开箱即用的程度。作为TTS入门来说,是一个相对优秀的选择。
当前GPT-SoVITS经历了:V1-V2-V3-V4-V2pro,一共5个版本的迭代,但是当前只有比较老的V2版本对SillyTavern(酒馆)的支持比较好。如果不需要接入酒馆,那么直接下载官方提供的最新V2pro整合包才是最佳选择。特别需要注意的是,不同版本预训练的语音模型,只能向下兼容,不能向上兼容。比如“崩坏3 GPT-Sovits V4 模型”就不能在GPT-Sovits V2版本上使用,需要特别留意!
二、下载对应版本
针对不同的使用需求,BLOG主推荐下载不同的整合包。
1、如上所述,如果需要训练语音模型,或者追求更好的合成效果,推荐直接下载GPT-SoVITS原始项目中提供的最新整合包,这个页面上面同时也会更新项目的新特性和教程。
2、如果需要接入酒馆,可以使用V3UCN大佬提供的修改整合包,但由于这个项目当前存在一些BUG,日语和韩语等外语无法合成,且看上去这位大佬已经很久没更新了,因此BLOG主自己修复了日语输出的问题,提供给大家下载。
三、如何使用TTS,合成语音
这里BLOG主用一个完整的工作流程,来展示如何使用TTS进行合成,并最终接入SillyTavern的完整步骤。推荐各位全部看完,然后各取所需。
1、下载上面BLOG主提供的项目包,并且解压缩。应该会得到以下的文件,这里简单介绍一下重要文件夹/文件的作用。
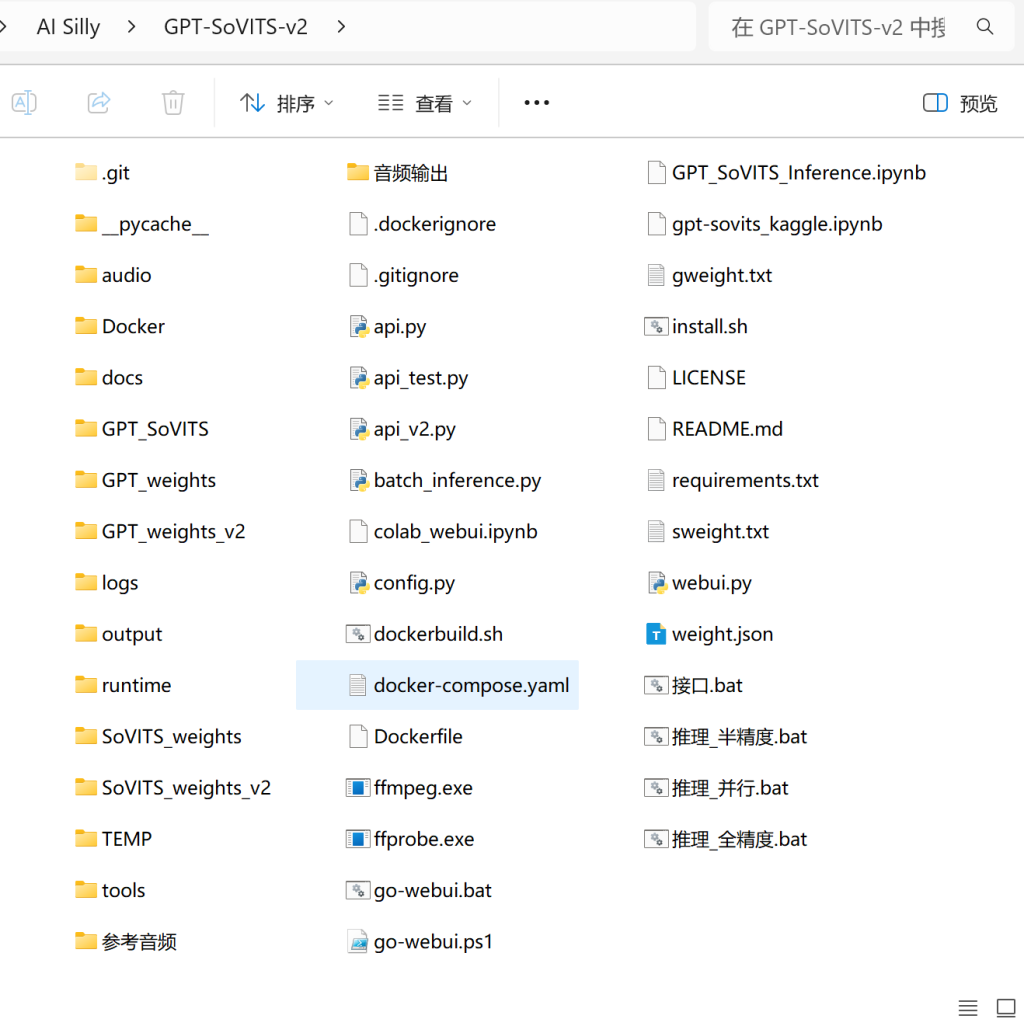
GPT_weights_v2:v2版本的预训练GPT模型存放位置,文件后续名为:ckpt。GPT模型通常负责理解文本内容,并生成与文本内容相匹配的韵律、情感等声学提示。
SoVITS_weights_v2:v2版本的预训练SoVITS模型存放位置,文件后续名为:pth。这个模型是核心的声音转换/合成器,它接收GPT模型输出的声学特征以及参考音频的音色信息,最终生成目标语音波形。
参考音频:这个文件夹存放的是3-10秒的音频文件,为TTS的主参考音频,语音合成时,会尽可能贴近这个原始音频的声音。通常为诶wav格式,且必须严格遵守时间范围。
音频输出:最后一次生成的语音合成音频,将保留在此。
go_webui.bat:官方提供的TTS语音训练WEB端入口,如果需要从头开始训练语音模型,请点击这里进入。
推理_并行.bat:由v3ucn大佬提供的TTS并行推理入口,只需要语音合成或需要接入酒馆的朋友,点击这里进入。
接口.bat:为酒馆或其他第三方调用该TTS提供API接口,当需要调用的时候点击这里打开。
2、加载模型
首先需要明确,BLOG主演示的版本是自用的GPT-Sovits-v2版本,能识别的预训练模型必须是V1或者V2的。这里BLOG主下载了一个“知更鸟”的V2版本预训练模型,解压缩之后如下图所示。
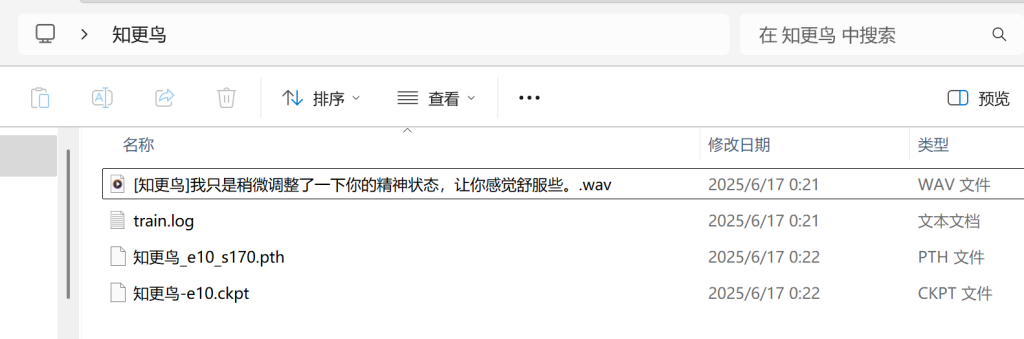
根据上文介绍的每个文件夹不同的功能,按照下图所示,将这几个文件复制到他们该去的地方:
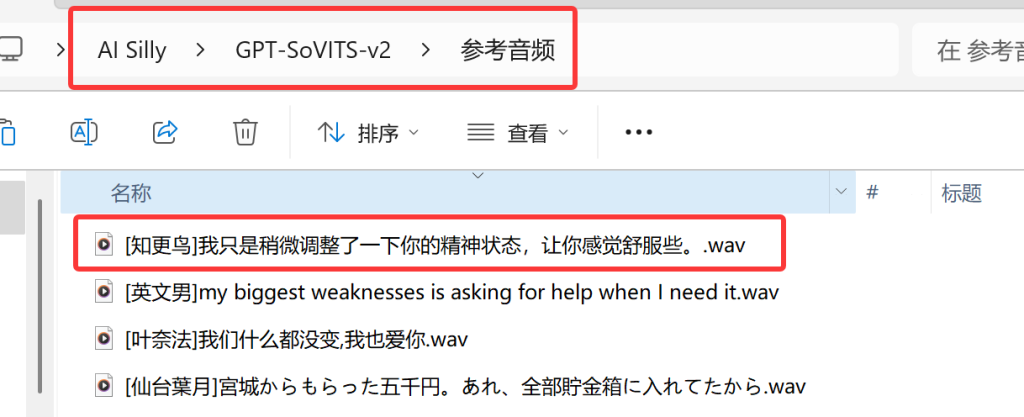
首先是wav文件,请注意重命名它的前缀:“[知更鸟]”,这有助于系统识别后面的内容。
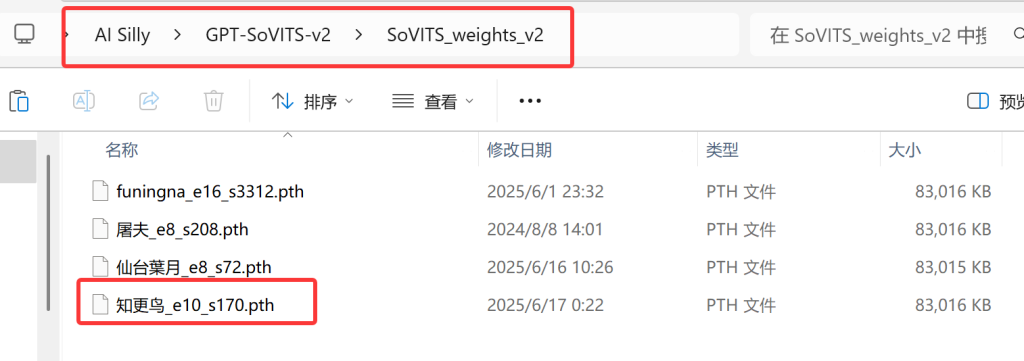
然后是SoVITS模型,V2的模型就要放进v2后缀的文件夹中,别放错了。
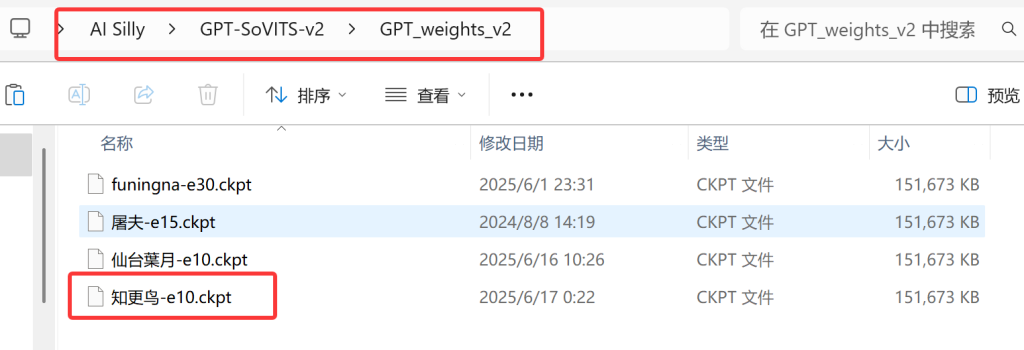
最后是GPT模型,同样v2版本的模型要放进后缀为v2的文件夹中,别放错了!
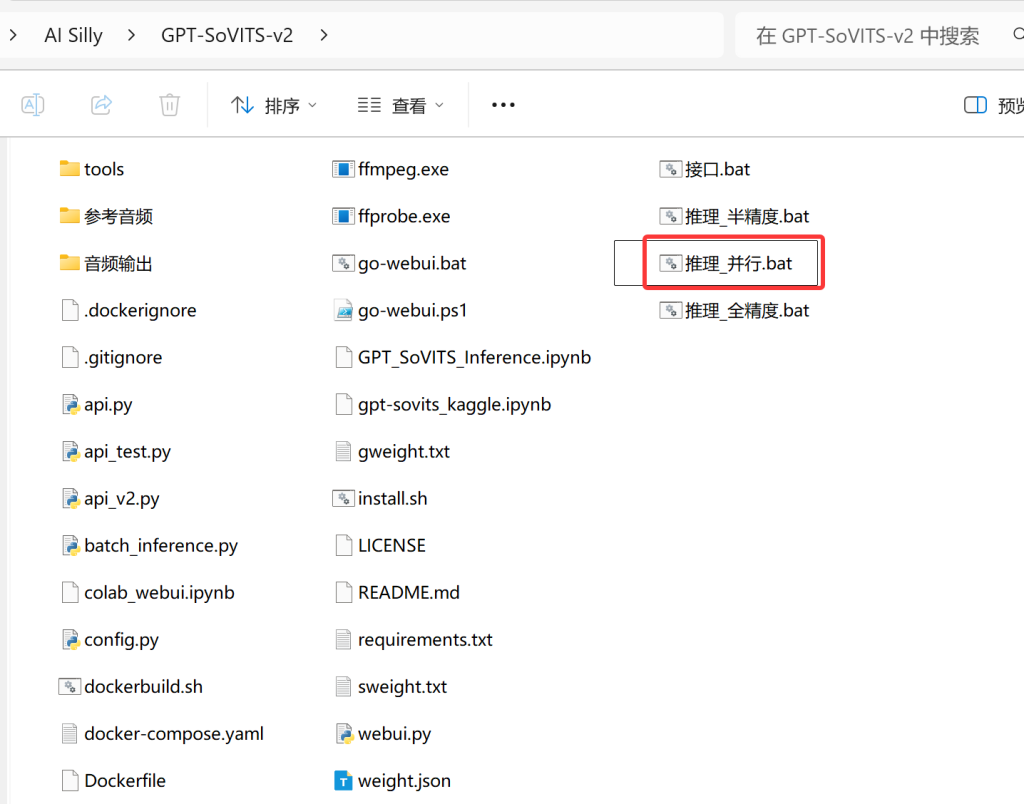
接着双击“推理_并行.bat”文件,随后会弹出一个黑色的命令提示符窗口,千万别手贱关闭,这是你TTS的本体。稍微等一会(大概10-30秒),会自动弹出浏览器窗口。
3、合成语音
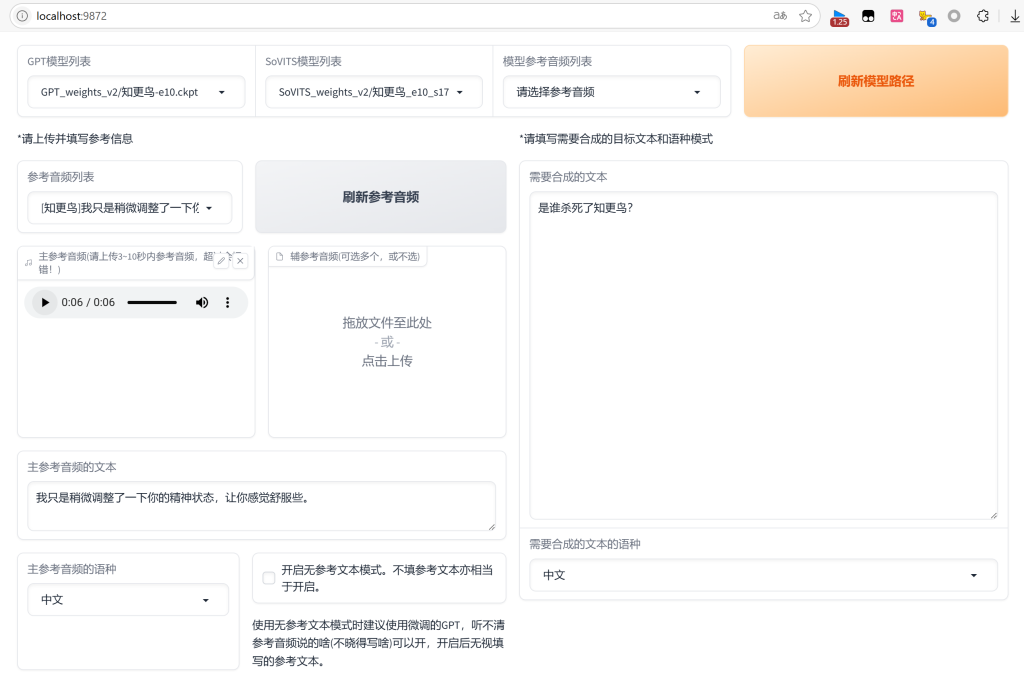
如果我们上面的操作正确,就可以在最上面的“GPT模型列表”和“SoVITS模型列表”上,看到知更鸟的模型名字,选择它就好。然后看下来,在“参考音频列表”下拉下来,也可以看到知更鸟的wav,也要选择好它。正确选择好,会看到“主参考音频的文本”上自动显示了音频说的文字。如果你看不到这个,可以回到上面一步,看看BLOG主说的对文件进行改名的步骤。
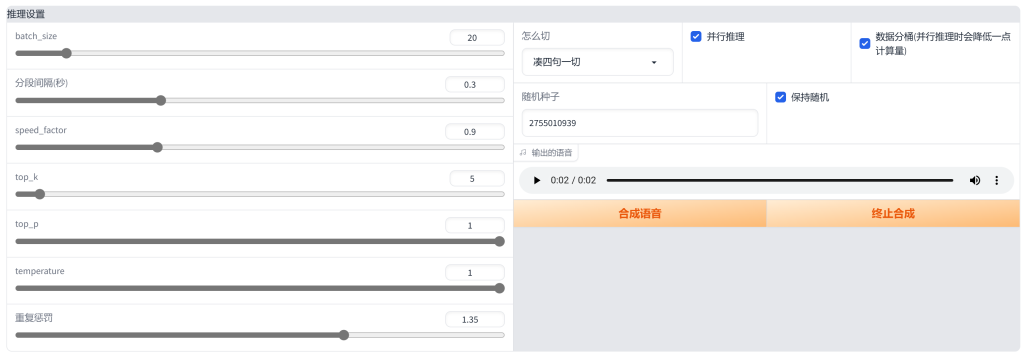
是谁杀死了知更鸟?(BLOG主耗时2秒)
真正的幸福应当是所有在虚无面前依旧挺立的事物。(BLOG主耗时6秒)
接着,你可以将想要合成的内容,填入“需要合成的文本”框框里面,这里BLOG主写了一句“是谁杀死了知更鸟?”。然后适当调整左边的参数(不懂的可以完全不动这里),最后点击“合成语音”。各位也可以听听BLOG主合成的这句话,顺便还合成了一句游戏中的台词,各位可以对比一下真人配音之间的区别。
四、SillyTavren(酒馆)加载GPT-SoVITS
1、注意,酒馆无需运行“推理_并行.bat”,只需要双击运行“接口.bat”,同样会弹出一个新的黑色框框,同样不能关闭这个框框!

2、运行酒馆(不会的去看BLOG主的这篇教程!),正常情况下,你应该能看到2个黑色框框,如下图所示。
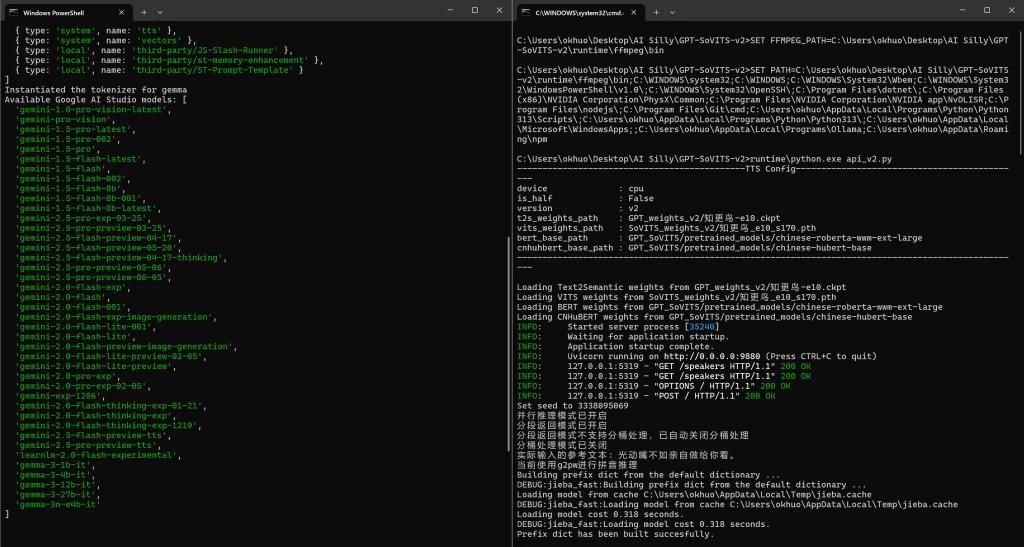
3、接着,一定要先打开一张任意卡片,这里以官方默认的塞拉菲娜为例。

然后根据下图,打开TTS插件,选中“GPT-SoVITS-V2”插件,然后按照需要勾选需要的内容。这里BLOG主选择的是:已启用、自动生成、只朗读引号内文本、跳过代码块、跳过标签块丽的内容。注意!不同的卡、预设都可能对这些选项产生影响,极端情况下,有些卡可能完全不适应生成,这属于无可奈何的情况,跟TTS无关。
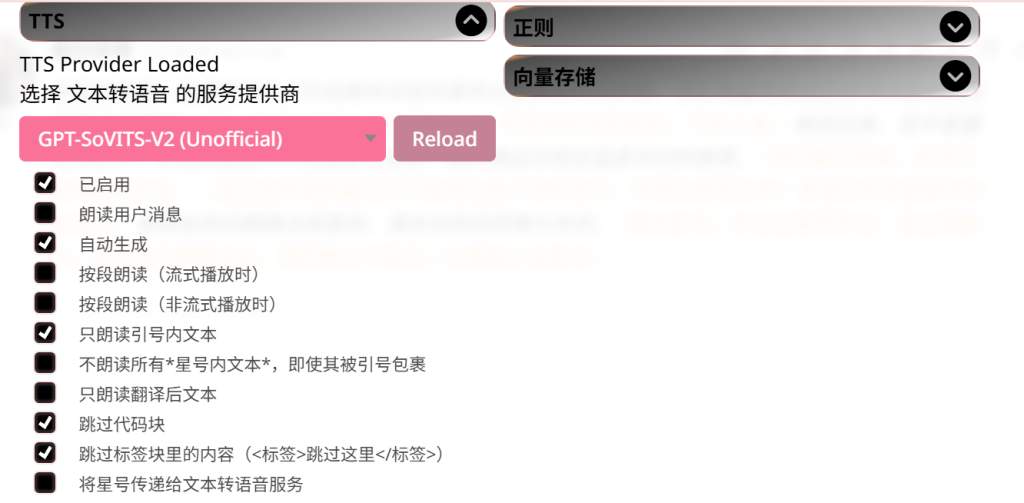
好了,接下来是为角色分配语音,其中“玲音”是BLOG主自己命名的主人公“User”、而塞拉菲娜则是这个故事的女主角,这里BLOG主分配了一个“[Krira]光动嘴不如亲自做给你看”语音,感觉是比较适配这个角色的语音风格。

全部设置完毕后!回到对话窗口,我们可以点击如图所示的小喇叭,来验证TTS是否生效。BLOG主的设置,是仅对角色的“语言”进行TTS合成,一来是节省合成时间,二来也是为了模拟GAL的游戏模式。确定能正常生成后,以后每次跟AI进行对话,在文字生成后,都会自动合成语音,并在合成完毕后自动播放。

当然如果你想要合成自己的声音,或者是某些动作女明星的声音,可以用音频剪辑软件,剪辑一些几秒的素材,扔到“参考音频”文件夹里,然后使用通用模型进行语音生成也是可以的。
五、当前存在的问题和解决方法
1、酒馆不支持V2之后的预设模型
这个问题需要等待酒馆插件的更新,等待未来插件支持V4甚至V2pro,我们就可以使用了(大概)
2、无法对合成语音进行微调
酒馆自身确实无法微调模型,但是其实我们可以用记事本打开GPT-SoVITS-V2文件夹下的“api_v2.py”文件,对默认加载参数进行调整。比如以下部分,可以自行改写默认加载的预训练模型,以达到更好的输出效果。实际上,api接口默认加载的GPT和SoVITS模型,是使用“推理_并行.bat”中最后加载的那组。这个文档还有许多可以调节的内容,作为进阶知识,BLOG主就不一一介绍了,有兴趣的可以自行调试,或者直接扔到Deepseek/Gemini中询问,你会得到非常有价值的提示。

3、不能远程调用
BLOG主发现了这个诡异的情况,即使是在局域网内,远端也无法调用本机的TTS进行输出,原因不明,如果未来解决了,BLOG主会修改这部分的内容,如果有大佬知道怎么解决,麻烦回复告知,谢谢!





8条评论
taixingyiji
因为现在插件有bug,无法修改gpt_sovits的地址,我这里手动调用save接口数据提交后,就可以使用局域网了。
找到save数据下面内容,
“GPT-SoVITS-V2 (Unofficial)”: {
“provider_endpoint”: “填入你的ip和端口”,
“format”: “wav”,
“lang”: “auto”,
“streaming”: true,
“text_lang”: “zh”,
“prompt_lang”: “zh”,
“voiceMap”: {
“[Default Voice]”: “[步非烟]我当然知道了”,
“User”: “[Default Voice]”,
“Seraphina”: “[Default Voice]”,
“Lucy”: “[Default Voice]”
}
},
huoyanyan
wa~o~感谢回复,回头试试
乔约木
请教大佬,这个save数据具体是指代哪个配置文件?
我如果想修改的话,应该打开哪个文件进行手动操作呢
热心网友
data文件夹 用户名文件夹的设置.json
111
这里有一个支持v4,v2pro的民间修改:https://www.bilibili.com/video/BV1WtM3zGE11
huoyanyan
6啊
yygtyhl
请问大佬,为什么并行推理能正常转日文,但是在酒馆里好像只能识别日文里的汉字并输出,该怎么办呢
huoyanyan
跟你的TTS支持语言有关系