AI蓝皮书:在huggingface上转换/创建不同量化标准的GGUF格式模型
这是AI蓝皮书系列教程的第四篇,直接承接从零开始了解本地AI部署教程,请确保对上一篇教程已经完全了解,再学习本篇教程!
本教程主要为了解决部分在huggingface上没有提供GGUF格式的量化模型的大模型,通过简单的方式转换成GGUF格式,以便个人用户在Ollama中拉取使用。通过该方法,能一键在线解决99%的huggingface模型在Ollama上的加载问题。另外,使用huggingface必须准备好梯子,这应该不用BLOG主再次细说了吧?
一、找到合适的模型
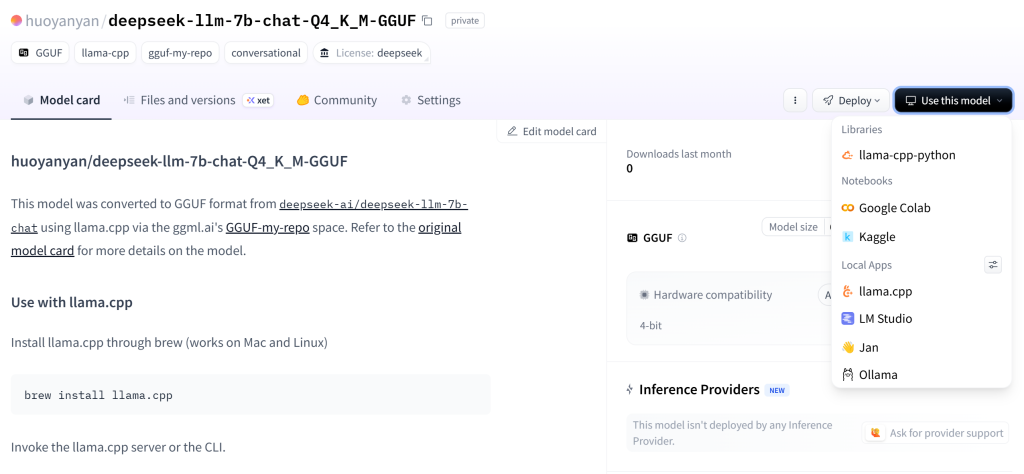
我们可以通过各种渠道找到自己想要的模型,比如BLOG主在deepseek官网最下方找到这个deepseek-llm-7b-chat模型的项目页面,点击右上角“Use this model”发现并没有提供Ollama的加载链接,证明这个模型并没有做GGUF的量化模型,不能被Ollama一键拉取。
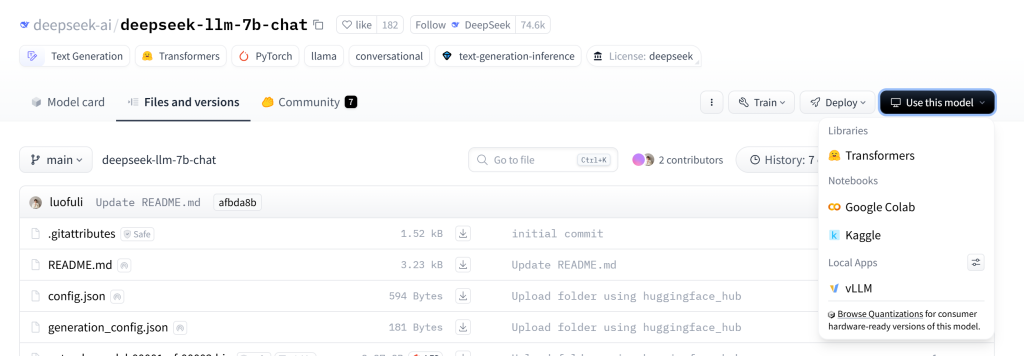
二、使用GGUF My Repo进行在线转换
接下来我们打开GGUF My Repo的链接,首先第一步点击上方黑色的“Sign in with Hugging Face”按钮进行登录。如果还没有注册Hugging Face的朋友,请先注册一个账号。对于玩AI大模型的人来说,这个网站就跟Github一样,未来是你家。
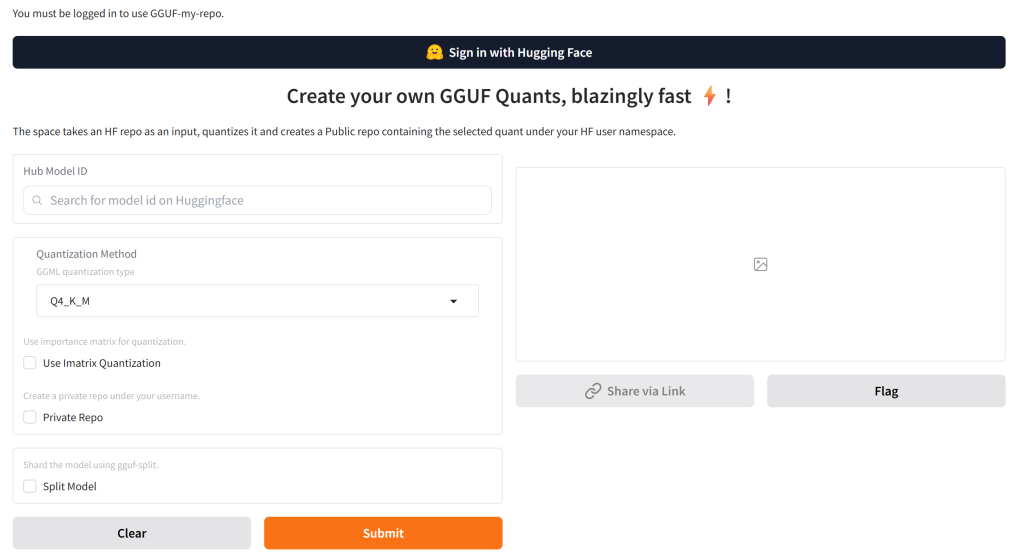
接下来,我们复制需要转换的模型名称/路径。如下图,在模型名称的右面,有一个很小的“Copied”按钮,点击一次就可以复制成功。

接着,将名字复制到“GGUF My Repo”页面的“Hub Model ID”栏目中,很容易就能找到我们需要转换的模型名字。
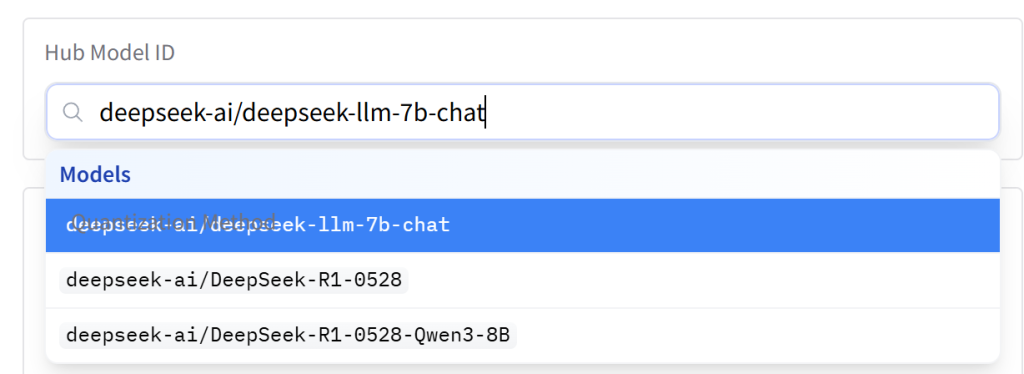
接下来BLOG主分别介绍几个选项分别代表的意思:
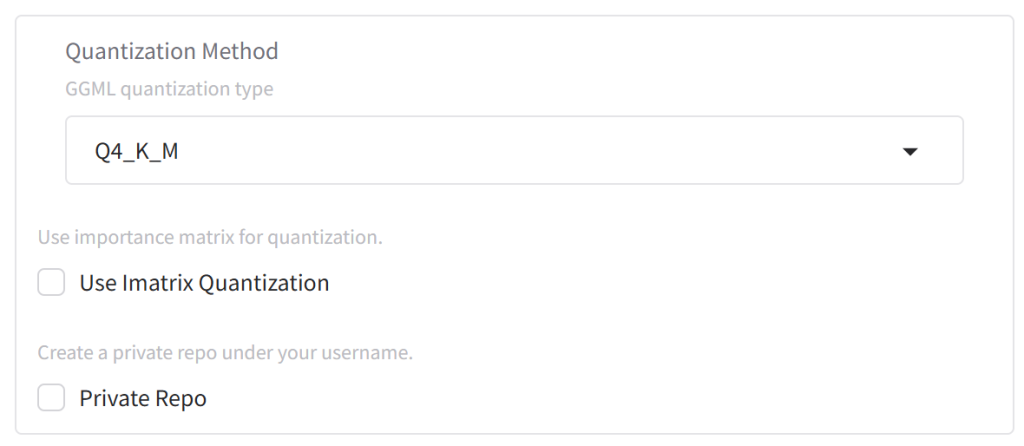
1、Quantization Method (量化方法)
GGUF 是目前 llama.cpp 推荐使用的模型文件格式,也是Ollama中默认支持的格式,如果需要Ollama中直接拉取模型跑起来,那么最简单的方式就是创建GGUF格式的量化模型。在“GGML quantization type”下拉选单中,我们可以看到一堆量化模式:
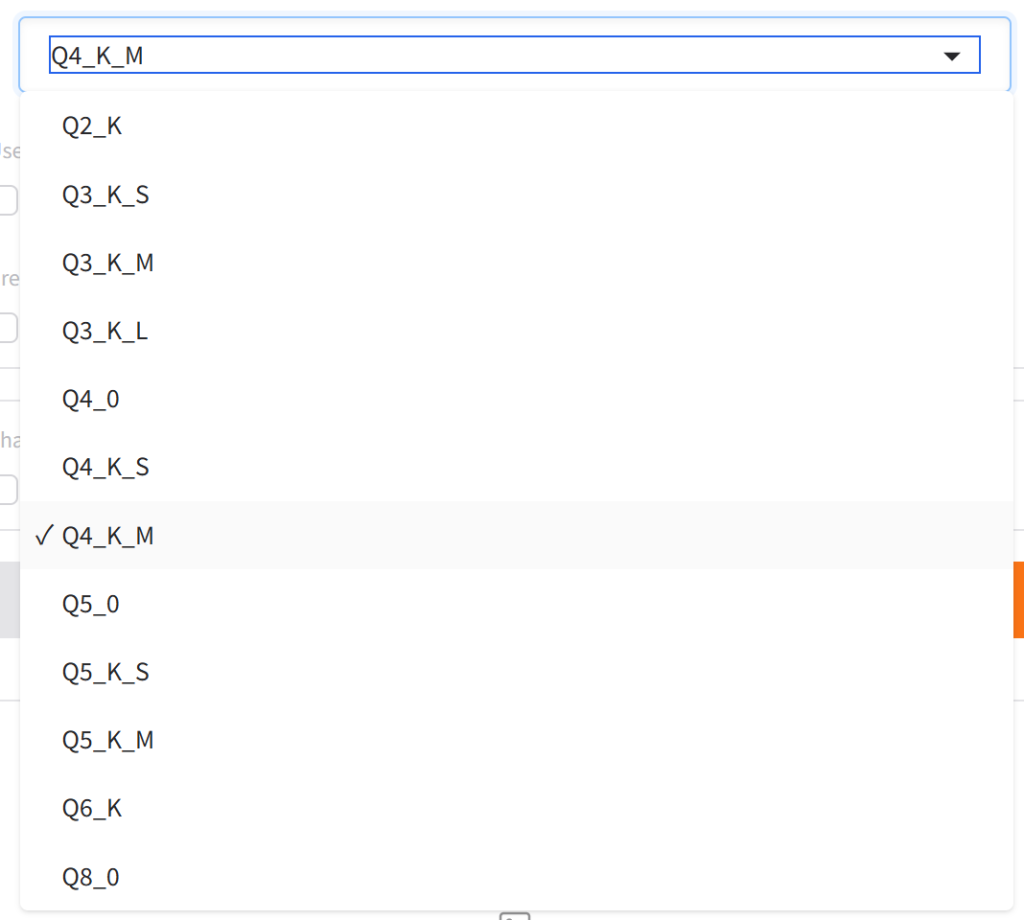
其中,Q+数字,代表模型的主要权重被量化到不同bit,比如Q4,代表量化为4-bit。第一位后续是K代表的是采用 “K-quant” 系列方法,这是 GGML/GGUF 中较新的、通常效果更好的量化方法。而第二位后续:S、M、L则分别代表“small/middle/large”三个不同的量化尺寸,L模型尺寸最大、推理速度最慢、模型质量效果最好、M适中、S则是模型尺寸最小、推理速度最块、模型质量效果相对最差。具体该采用什么方法、量化到什么精度,请查看上一篇教程:从零开始了解本地AI部署。BLOG主自用的16G显存显卡,最终选择的是最甜点的Q4_K_M。
2、Use Imatrix Quantization (使用重要性矩阵量化)
“Imatrix” (Importance Matrix) 是一种通过分析模型在一组校准数据上的激活值来确定哪些权重对模型性能更重要的方法。启用此选项后,量化过程会更侧重于保护这些重要权重,从而在相同的比特率下可能获得更好的量化后模型质量。
如果更进一步去解释,”Imatrix”会在模型量化之前,使用一个校准数据集 (calibration dataset) 来运行模型。通过分析模型在校准数据上的行为,计算出每个权重对于模型整体性能的“重要性”。这个信息被编码成一个“重要性矩阵”。然后在对模型权重进行静态量化时,这个重要性矩阵会指导量化过程。例如,更重要的权重可能会被分配更多的比特,或者量化误差会优先在不重要的权重上产生,以最大限度地减少对重要权重精度的损害。
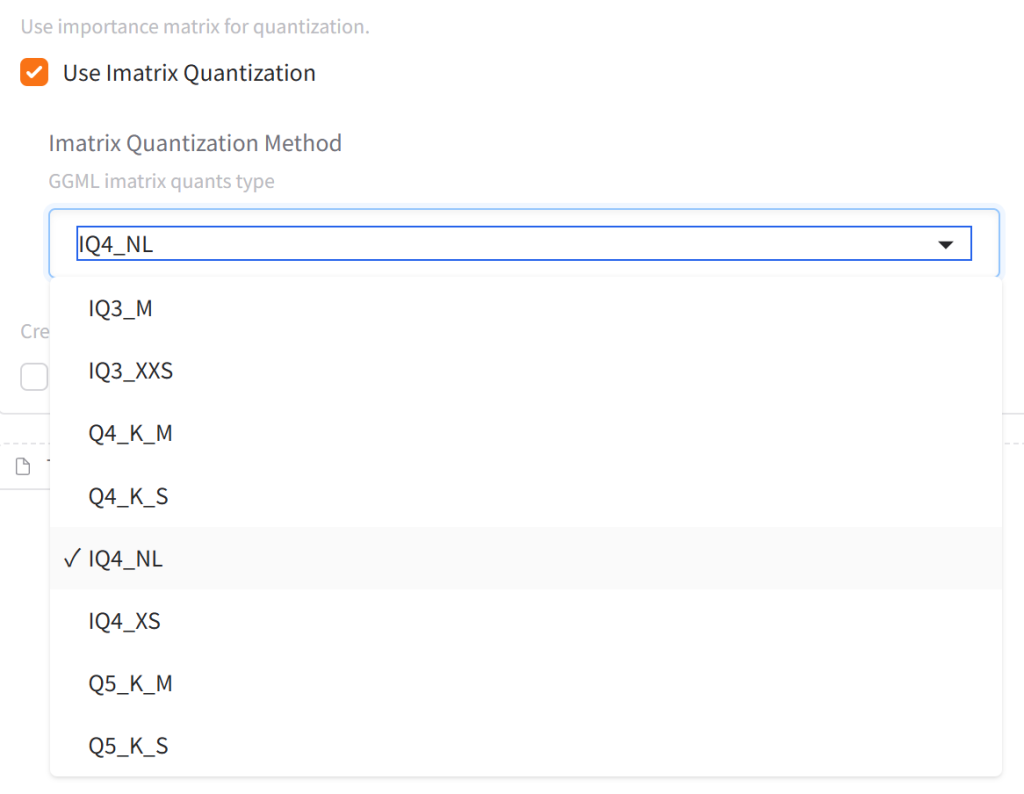
跟上面“GGML imatrix quants type”类似,主要对出了首字母“I”,代表使用”Imatrix”重要性矩阵量化。后缀“NL”是一种专门为重要性矩阵设计的量化类型,通常非常高效,能在较小的空间内存储重要性信息,一般我们都会默认选择带有NL的选项。XS/XSS,这两个其实是S的拓展,代表“Extra Small”和“Extra Extra Small”,推理速度会进一步加快。
3、Private Repo
在GGUF My Repo中转换/创建GGUF模型,会视为用户“发布”了一个新模型。Private Repo选项勾选后,可以确保这个模型不对外公开,仅为私人使用。反之不勾选,则会将这个模型在Huggingface社区中公开。
4、Training Data File (训练数据文件)
使用重要性矩阵 (Imatrix) 进行量化时,系统需要一些数据来“校准”或“衡量”模型中不同权重的重要性。这个“训练数据文件”实际上就是指校准数据集 (calibration dataset) 或代表性数据集 (representative dataset)。这部分训练文件,通常需要模型的制作方提供,个人并不能自行制作,因此如果官方没有提供这个训练数据,就不能使用Imatrix 进行量化了。
5、Split Model (分割模型)
这个选项允许你在量化完成后,将生成的单个 GGUF 模型文件分割成多个更小的部分(称为 “shards”)。Hugging Face 通常建议单个文件不要超过 5GB (虽然可以上传更大的,但分片更友好)。如果你的量化后模型非常大(比如超过 5GB 或 10GB),分割成多个小文件可以方便上传和分享,在拉取过程中,遇到网络波动,损失可能也没那么大。
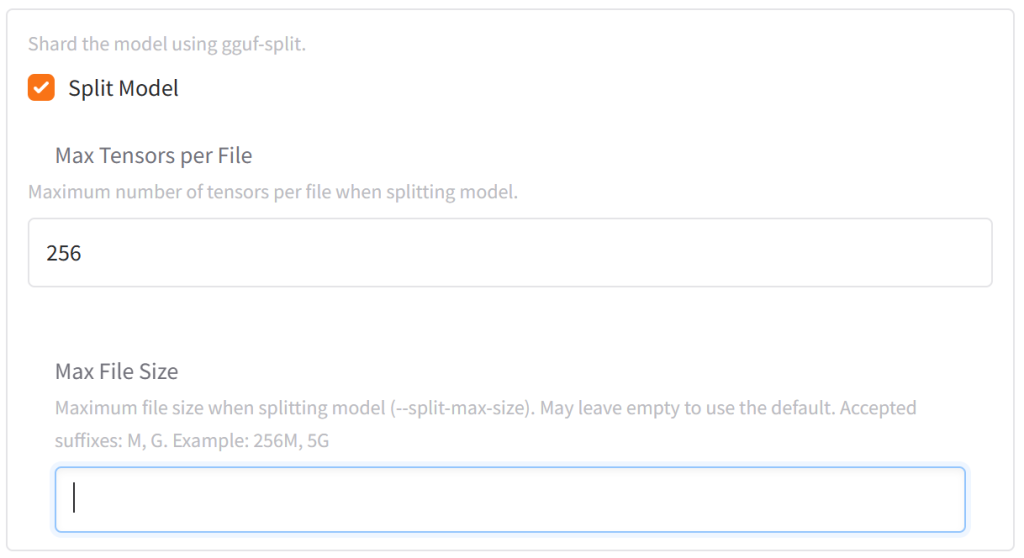
“Max Tensors per File” (每个文件的最大张量数)。一个 GGUF 模型文件内部是由多个张量 (tensors) 组成的,这些张量存储了模型的权重、偏置等参数。这个选项设置了在分割模型时,每个生成的小文件(分片/shard)最多可以包含多少个张量。默认的256就是个比较通用的数值,基本上这个项目不会需要改动。
“Max File Size” (最大文件大小),这个选项直接控制了每个分割后的小文件的最大体积。这是最常用和最直观的分割控制方式。大多数情况下,如果一个模型太大,会选择4G/4096M进行分割。
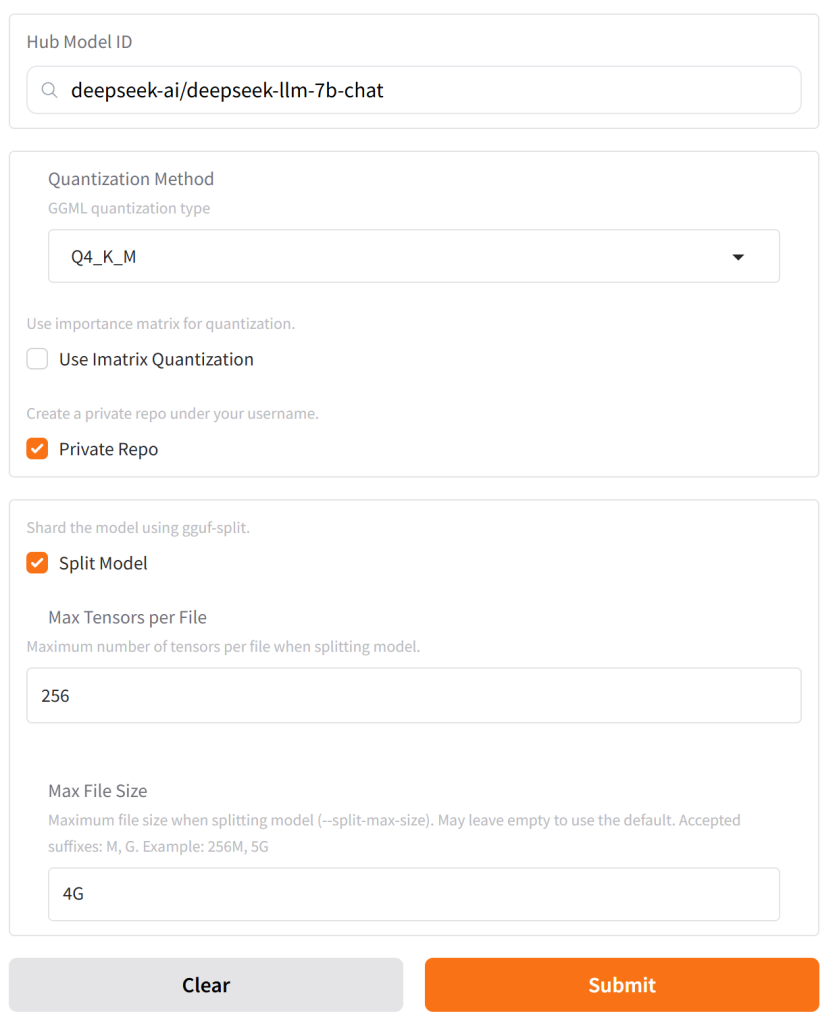
最后,如上图,这是BLOG主最后的设置,全部搞定之后,点击“Submit”之后,系统就会自动进行转换。右上角会看到剩余时间进度条(但非常不准)。这时候可以去干点别的事情,等全部内容完成之后,进入个人页面,就可以看到以自己用户名建立的新模型上传到了Huggingface上。点击右上角“Use this model”,就可以看到Ollama拉取命令,接着就可以根据BLOG主之前的教程,使用Ollama加载使用了!
三、总结
其实BLOG主还挺奇怪的,全网都没有提及这个最简单、也是最实用的,将HuggingFace模型转换GGUF的方法,大多数搜索出来的教程都是使用llama.cpp进行转换,对于很多刚接触AI大模型的朋友来说,操作繁琐并不友好。而使用HuggingFace提供的方案,不仅更为简单方便,其稳定性也有充足的保障。




